Wat is webscraping en hoe werkt het in de digitale wereld?
Gegevens(Data) en informatie zijn twee termen die vaak door elkaar worden gebruikt, maar er is een opmerkelijk verschil tussen beide. Gegevens verwijzen bijvoorbeeld naar stukjes informatie, maar niet naar informatie zelf. Aan de andere kant is informatie(Information) een verzameling gegevens die op een zinvolle manier wordt verwerkt. Met de overweldigende gegevens die op internet beschikbaar zijn, worden verschillende benaderingen zoals Web Scraping , Web Harvesting of Web Data Extraction gebruikt om bruikbare en baanbrekende inzichten te genereren via internetgebruik(Internet) . Maar wat ze precies betekenen in de online wereld. Laten we kijken!
Hoe werkt webscraping?
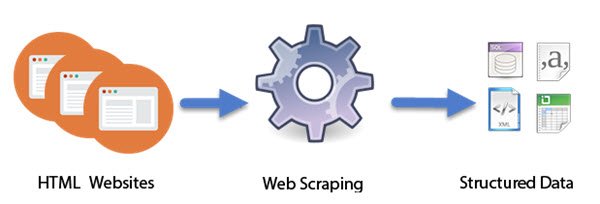
Computerprogramma(Computer) 's die zijn ontworpen als intelligente(Intelligent) bots, doen het werk van webscraping . In tegenstelling tot schermschrapen, waarbij alleen pixels worden gekopieerd die op het scherm worden weergegeven, extraheert webschrapen onderliggende HTML -code en daarmee gegevens die zijn opgeslagen in een database. De aanpak is behoorlijk populair geworden. Het wordt zelfs beschouwd als een van de essentiële vaardigheden om te verwerven in de digitale wereld van vandaag. Het heeft een aantal geweldige toepassingen bij het samenstellen van grote datasets, fundamenteel voor technieken zoals-
- Big data-analyse(Big Data Analytics)
- Machinaal leren
- Kunstmatige intelligentie(Artificial Intelligence)
Met de snelle uitbreiding van digitale informatie is toegang tot Big Data via Web Scraping of Web Data Extraction - aanpak veel eenvoudiger geworden. Dat gezegd hebbende, kan Web Scraping worden gebruikt voor digitale bedrijven die afhankelijk zijn van gegevensverzameling in zowel legitieme(Legitimate) als onwettige gevallen. De eerste bevat voorbeelden van Benevolent Web Scraping(Benevolent Web Scraping Examples) , terwijl de laatste voorbeelden van Malicious Web Scraping bevat .
Welwillende voorbeelden van webscraping
- Bots van zoekmachines(Search) crawlen een site en analyseren de inhoud om een rang toe te kennen op basis van bepaalde bevindingen, zoals Google .
- Prijsvergelijkingssites(Price) die bots inzetten om automatisch prijzen van producten op te halen
- Marktonderzoeksbedrijven(Market) die scrapers gebruiken om gegevens uit sociale media te halen (bijvoorbeeld voor sentimentanalyse, persoonlijke voorkeuren, enz.).
Voorbeelden van kwaadaardige webscraping
Webscraping voor illegale doeleinden kan ernstige financiële verliezen veroorzaken als gegevens worden geëxtraheerd zonder toestemming van website-eigenaren. De twee meest voorkomende gebruiksscenario's van Malicious Web Scraping zijn prijsschrapen en diefstal van inhoud.
- Prijsschrapen(Price Scraping) - Scraper - bots inspecteren concurrerende bedrijfsdatabases om toegang te krijgen tot prijsinformatie, rivalen te ondermijnen en de verkoop te stimuleren.
- Diefstal van inhoud(Content Theft) – Deze onwettige activiteit omvat grootschalige diefstal van inhoud van een doelwebsite. Typische doelwitten zijn voornamelijk online productcatalogi en websites die vertrouwen op digitale inhoud om zaken te doen.
Ik hoop dat dit helpt!

About the author
Ik ben een ervaren software-engineer met meer dan 10 jaar ervaring in het Windows-ecosysteem voor app- en bestandsbeheer. Ik ben ook een veteraan in het ontwikkelen van systemen en beveiligingsoplossingen voor bedrijven en overheden. Mijn ervaringen in beide arena's geven me een uniek perspectief op wat goede software, systemen en beveiliging maakt en hoe deze efficiënt te bouwen.
Related posts
Geen internetverbinding, maar wordt weergegeven als Verbonden met internet
Wat is Bitcoin, de digitale valuta?
Wat gebeurt er met uw online rekeningen als u overlijdt: Digital Assets Management
Wat is Dark Web of Deep Web? Toegang en voorzorgsmaatregelen.
Voordelen van het nemen van Digital Detox en hoe u dit aanpakt
Kunt u geen verbinding maken met internet? Probeer de complete internetreparatietool
Lijst met beste gratis internetprivacysoftware en -producten voor Windows 11/10
Geblokkeerde of beperkte websites deblokkeren en openen
Migreer snel van Internet Explorer naar Edge met deze tools
Cybercriminaliteit en de classificatie ervan - Georganiseerd en ongeorganiseerd
Waar staan veelvoorkomende HTTP-statuscodefouten voor?
Een internetverbinding instellen op Windows 11/10
31 Beste webschraptools
Domain Fronting uitgelegd samen met gevaren en
Een gedeelde internetverbinding thuis gebruiken
Een vertrouwde site toevoegen in Windows 11/10
10 Web 3.0-voorbeelden: is het de toekomst van internet?
Internet werkt niet na een update op Windows 11/10
Internetbeveiligingsartikel en tips voor Windows-gebruikers
Wat zijn geparkeerde domeinen en Sinkhole-domeinen?